Architecture Overview
The proposed Multi-Modal Spectro-Spatio-Temporal Encoder (MMSSTE) integrates dual-form attention mechanisms for efficient processing of Sentinel-1 and Sentinel-2 satellite time series.

Figure 1: Overview of the proposed multi-modal spectro-spatio temporal architecture, composed of: a modality specific spectro-spatial encoder (noted gS1 resp. gS2), a temporal fusion encoder, an upsampling operation with pixel shuffle (P.S) and a task specific decoder layer.
Dual-Form Mechanisms
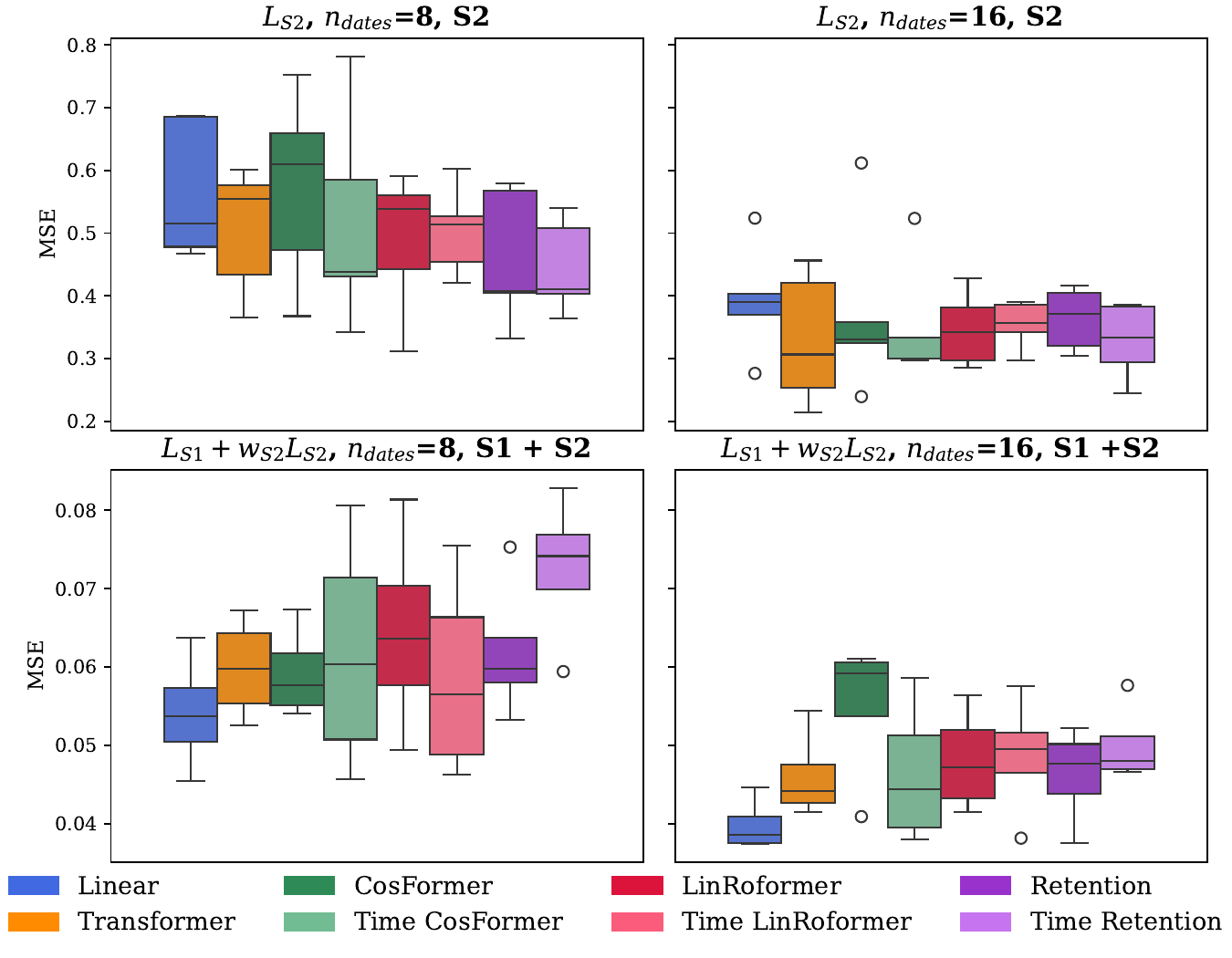
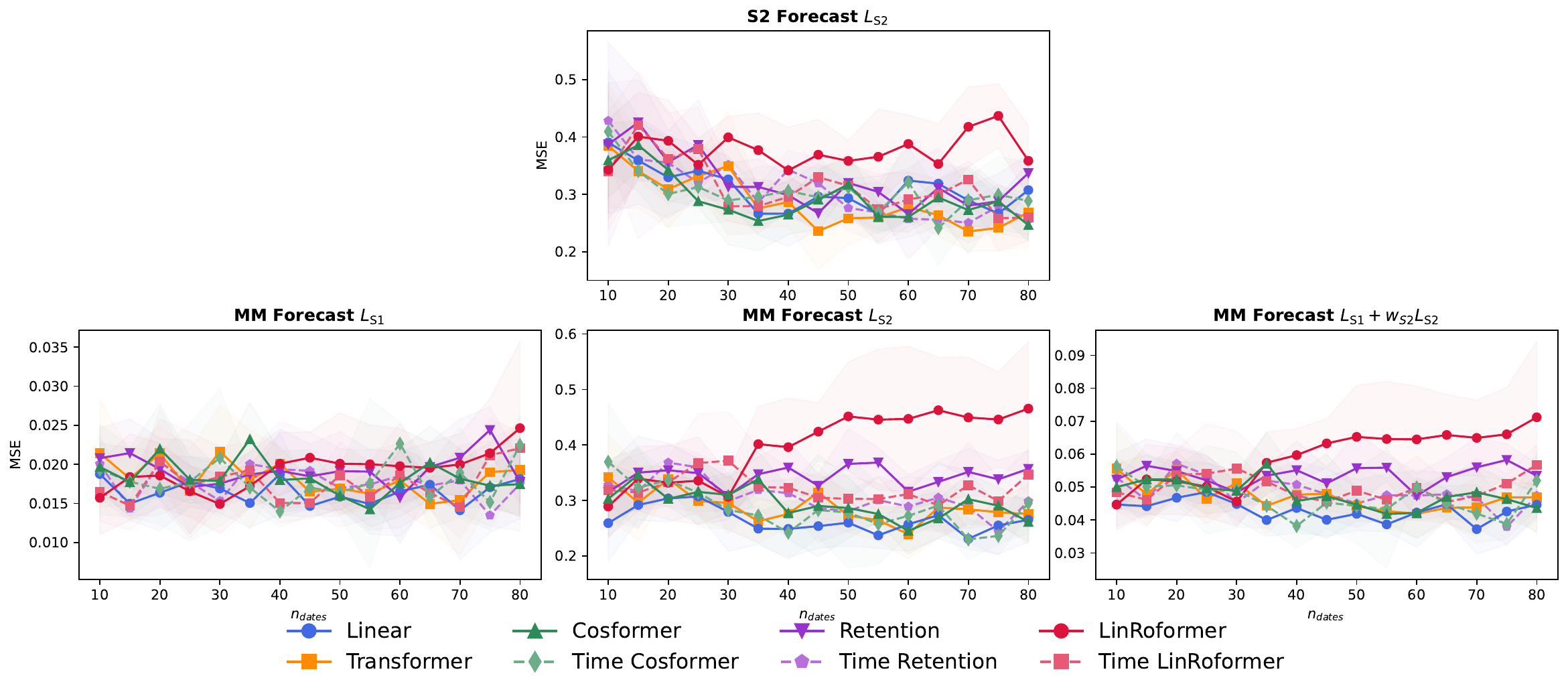
We compare several dual-form attention mechanisms:
- Linear Transformer: Uses separable similarity functions for efficient computation
- CosFormer: Integrates cosine-based reweighting for token proximity
- LinRoFormer: Applies Rotary Positional Encoding (RoPE) to linear attention
- Retention: Incorporates decay mechanisms with RoPE
Additionally, we propose temporal variants (Time CosFormer, Time LinRoFormer, Time Retention) that compute distances based on actual acquisition dates rather than sequence indices, addressing SITS temporal irregularity.